|
I am a researcher at Tencent Video, working on multimodal video generation & world models for filmmaking. I got my PhD degree (2021 ~ 2025) from The Hong Kong Polytechnic University, fortunately supervised by Prof. Bo Yang. My PhD research focused on 3D reconstruction and scene understanding. Prior to that, I got my M.Eng and B.Eng degrees (Honors Youth Program) from Xi'an Jiaotong University. During my PhD study, I interned at TikTok (San Jose, CA) with Xinyu Gong. During my M.Eng study, I interned at SenseTime with Dongliang Wang, and Tencent Robotics X with Wanchao Chi. |

|
|
|
NEW!
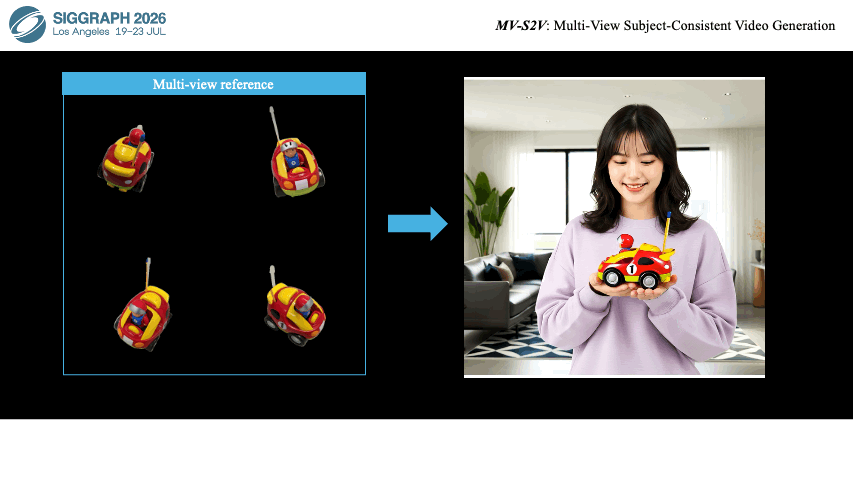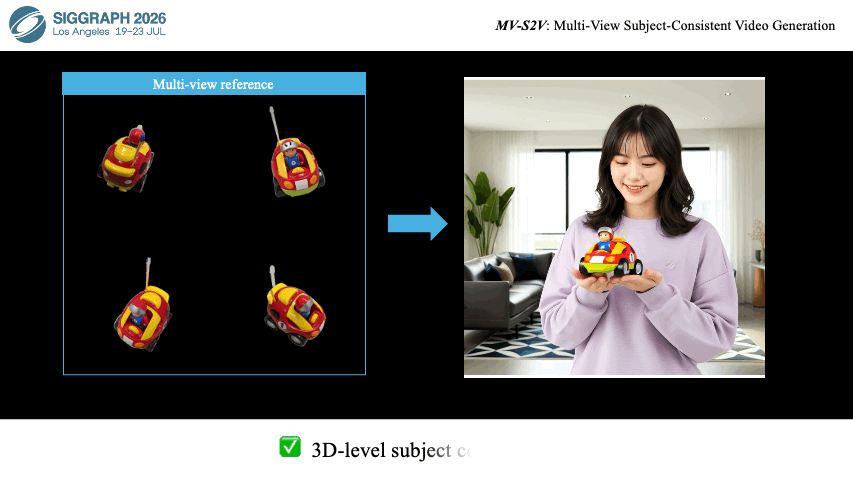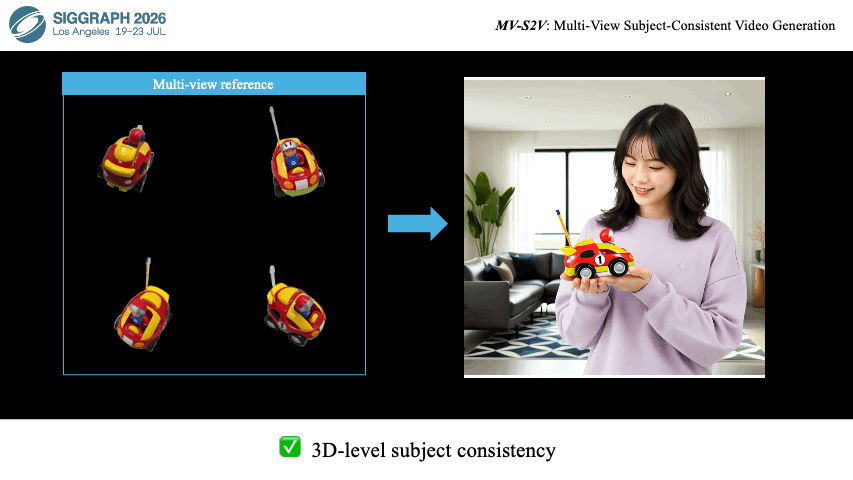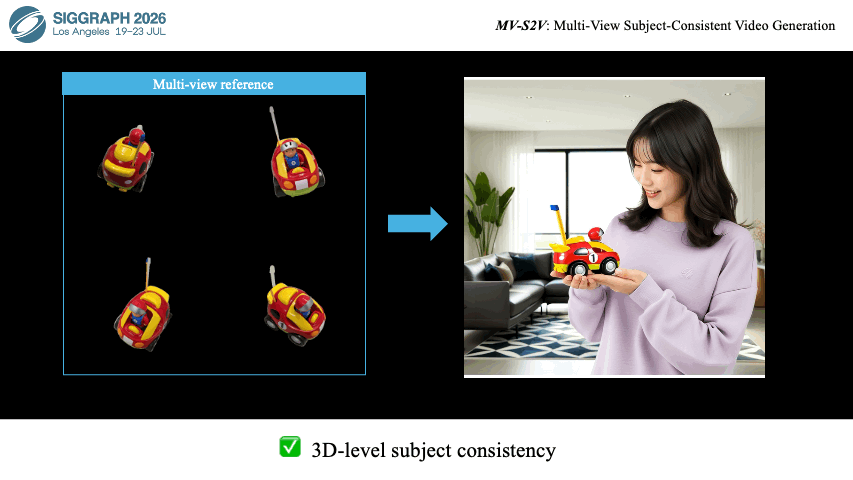
|
Ziyang Song, Xinyu Gong, Bangya Liu, Zelin Zhao ACM SIGGRAPH, 2026 arXiv Project Page Code |
NEW!

|
Zelin Zhao, Xinyu Gong, Bangya Liu, Ziyang Song, Jun Zhang, Suhui Wu, Yongxin Chen, Hao Zhang Computer Vision and Pattern Recognition Findings (CVPR Findings), 2026 arXiv Project Page |

|
Jinxi Li, Ziyang Song, Bo Yang International Conference on Computer Vision (ICCV), 2025 arXiv Code |
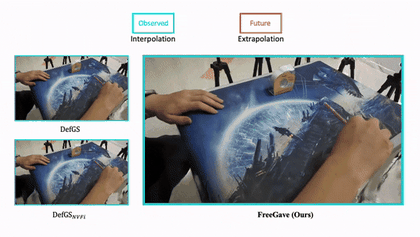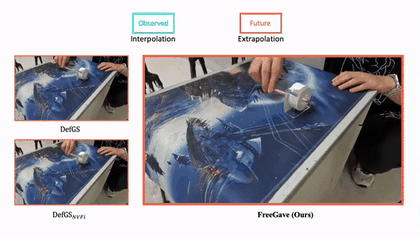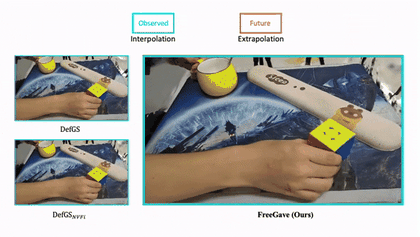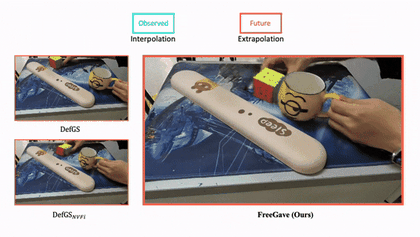
|
Jinxi Li, Ziyang Song, Siyuan Zhou, Bo Yang Computer Vision and Pattern Recognition (CVPR), 2025 arXiv Code |

|
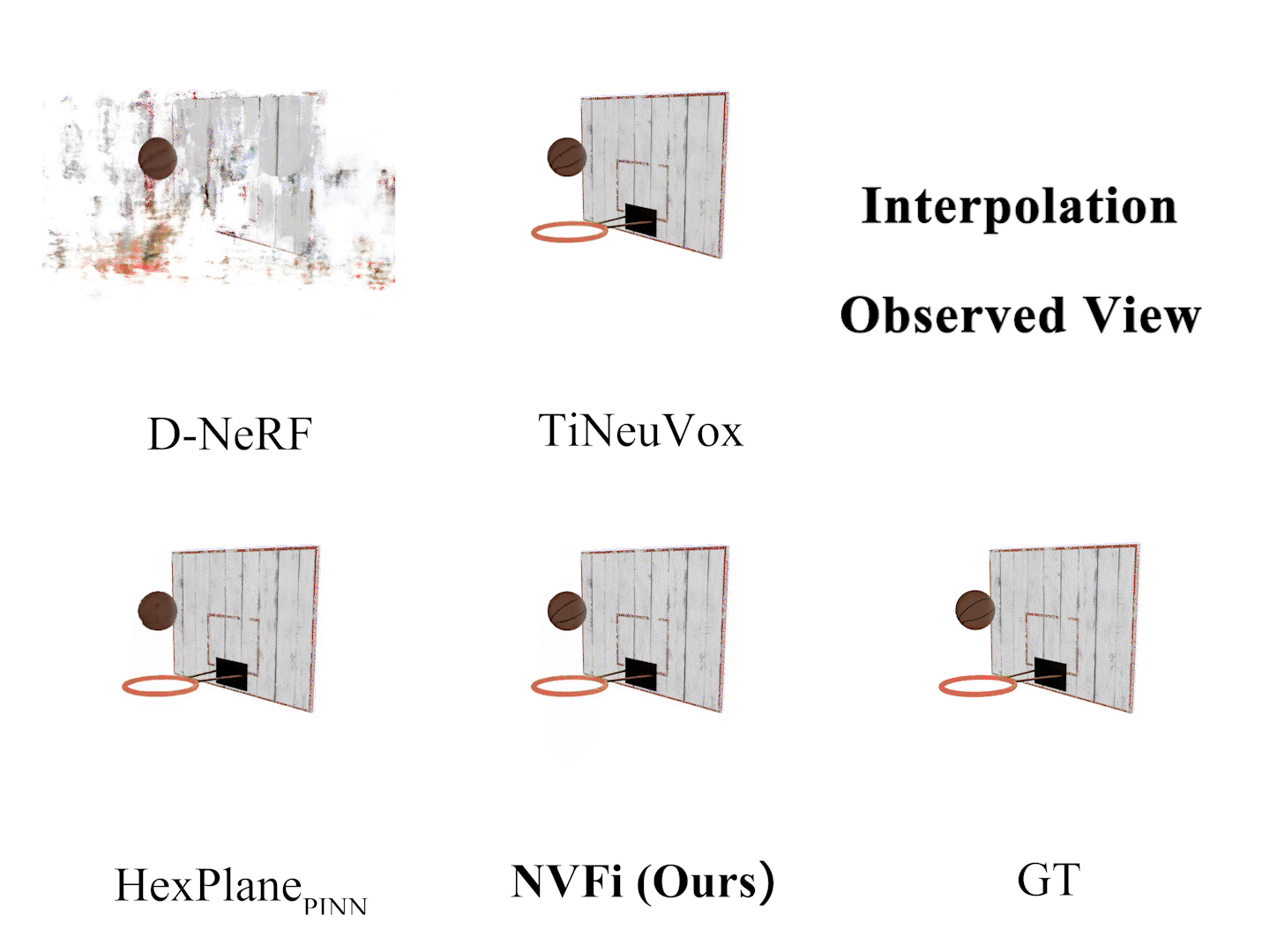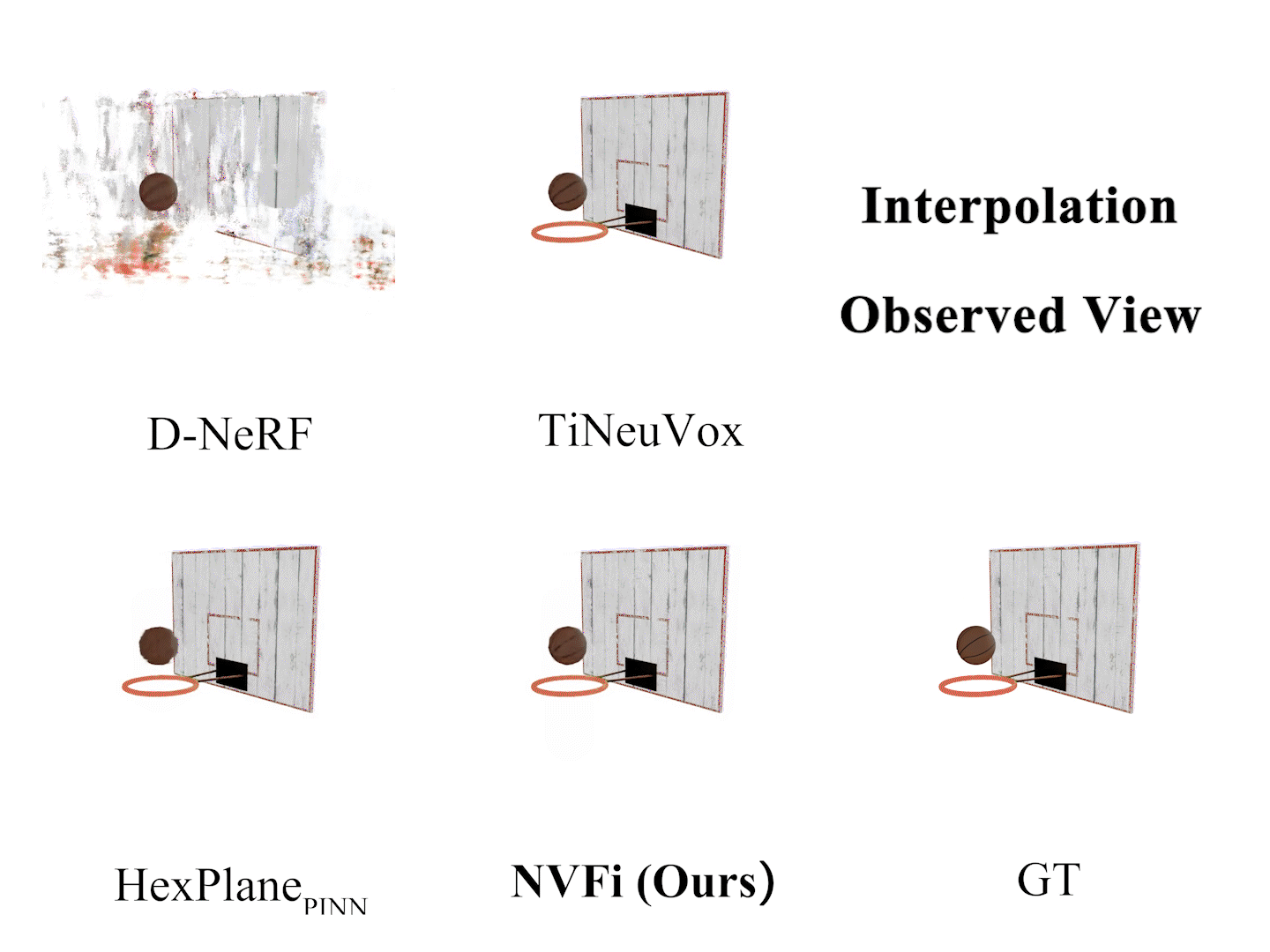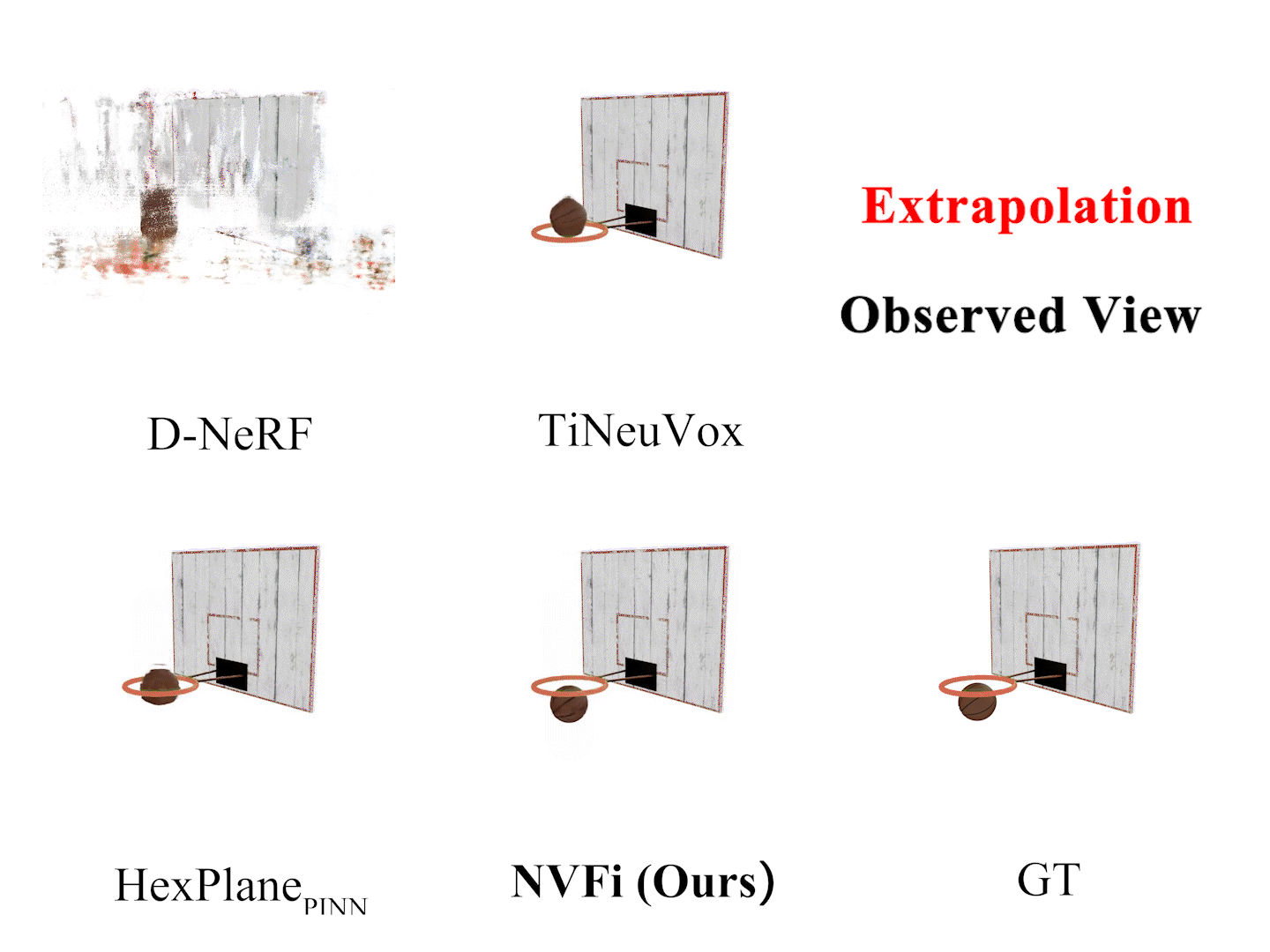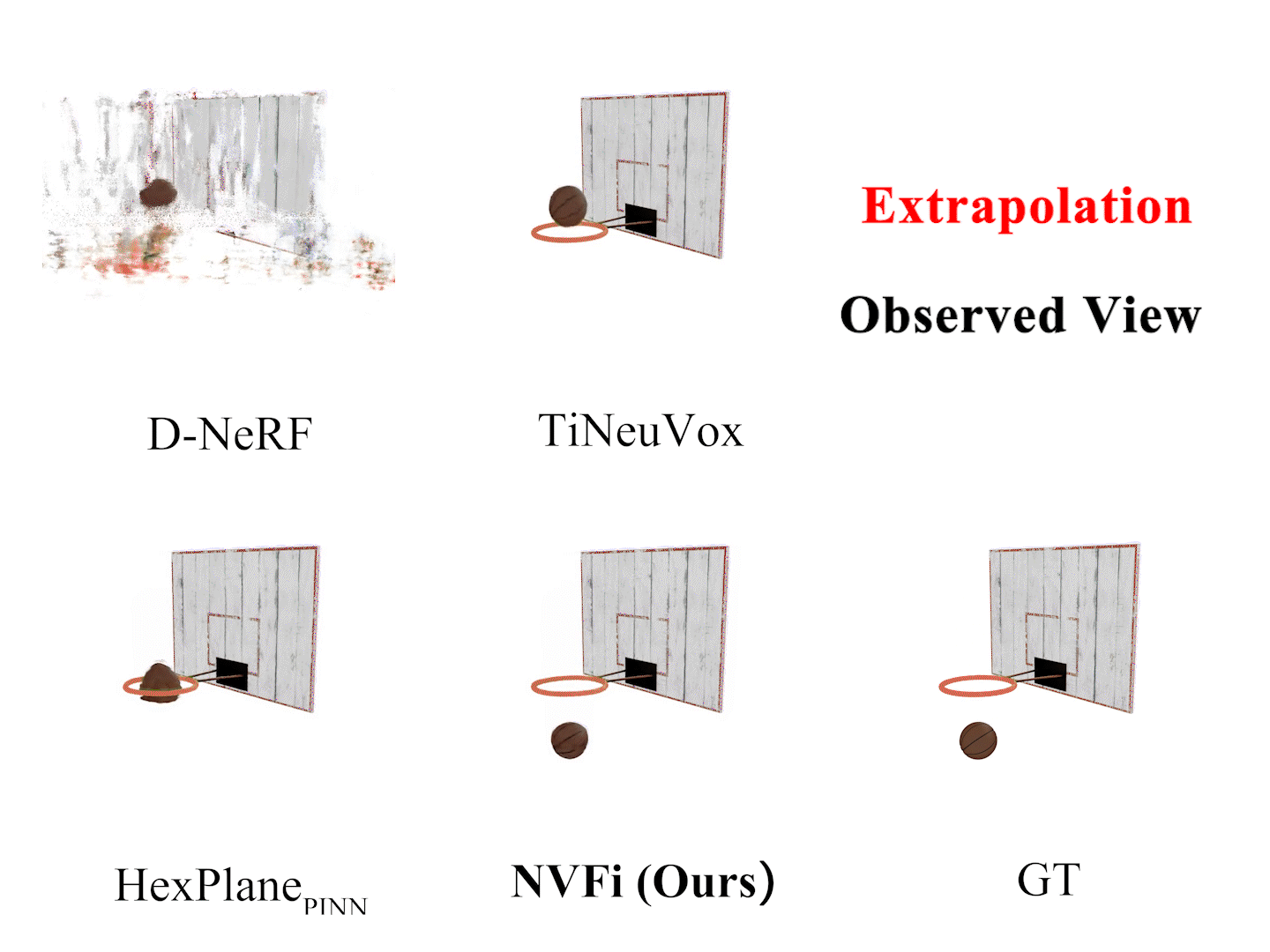
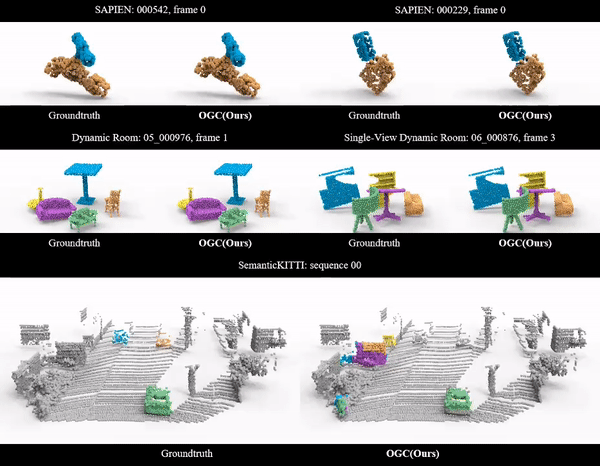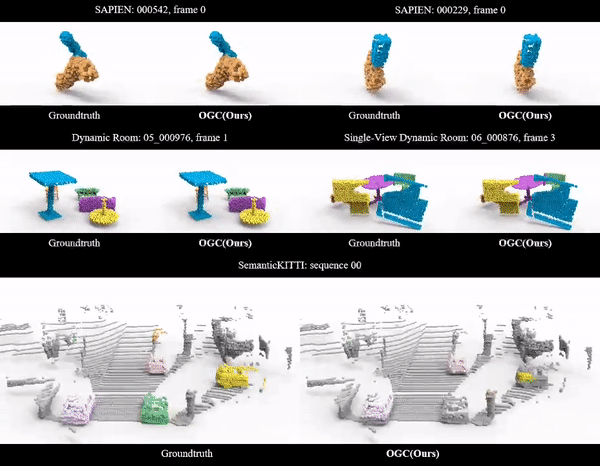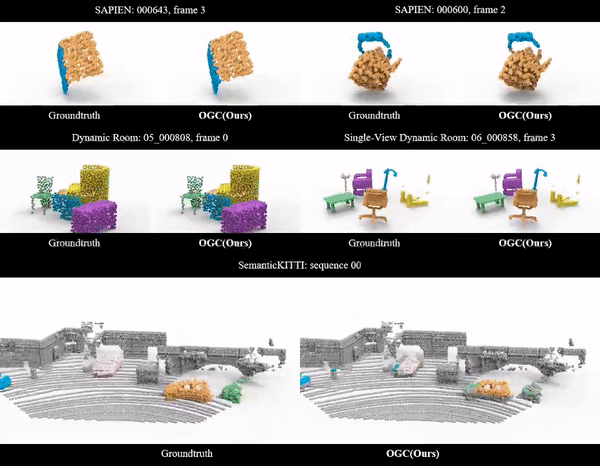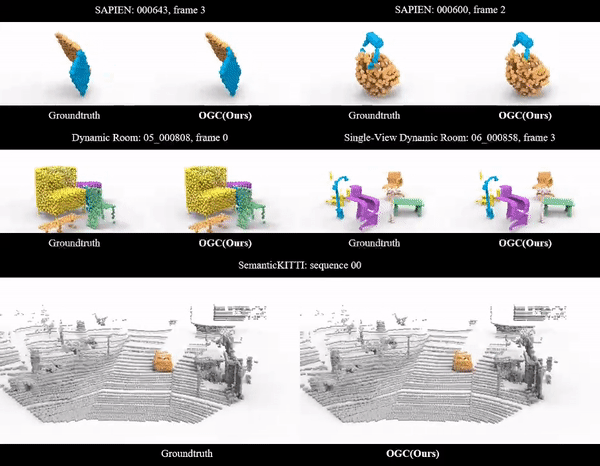
Ziyang Song, Jinxi Li, Bo Yang International Conference on Machine Learning (ICML), 2024 arXiv Video Code |
|
Jinxi Li, Ziyang Song, Bo Yang Advances in Neural Information Processing Systems (NeurIPS), 2023 arXiv Code |
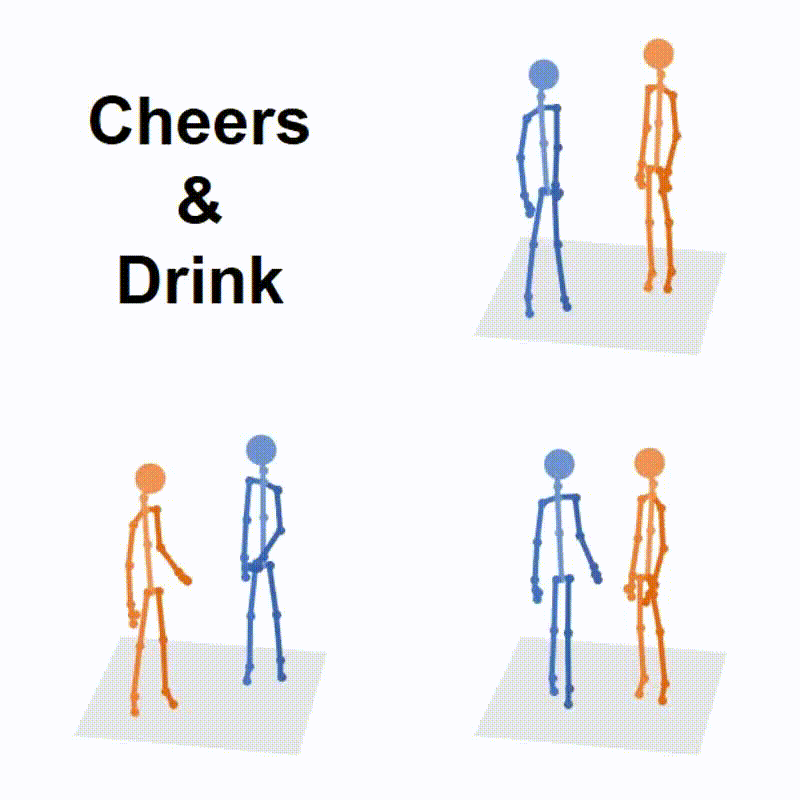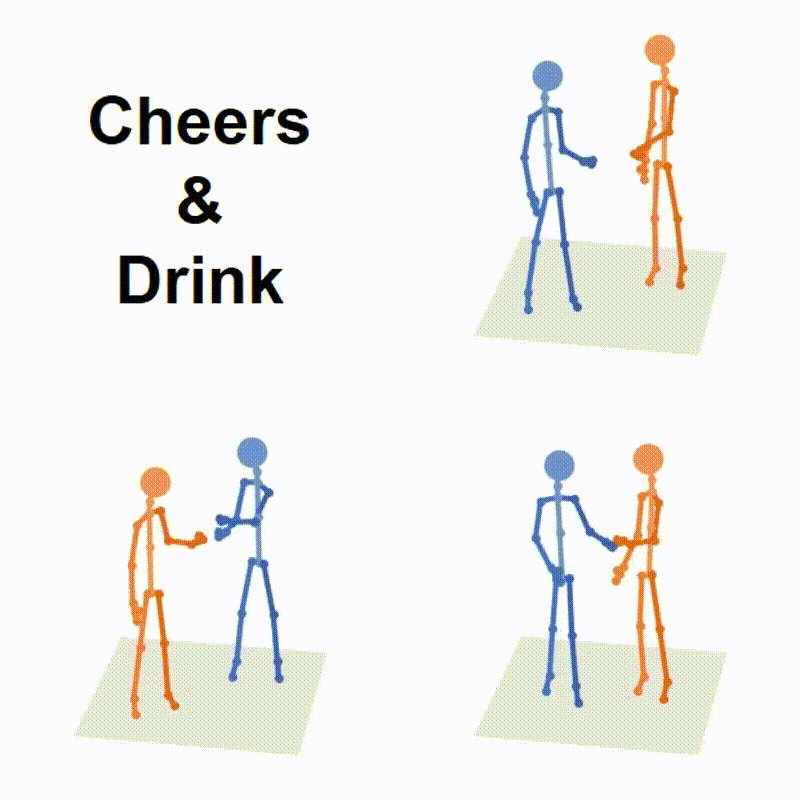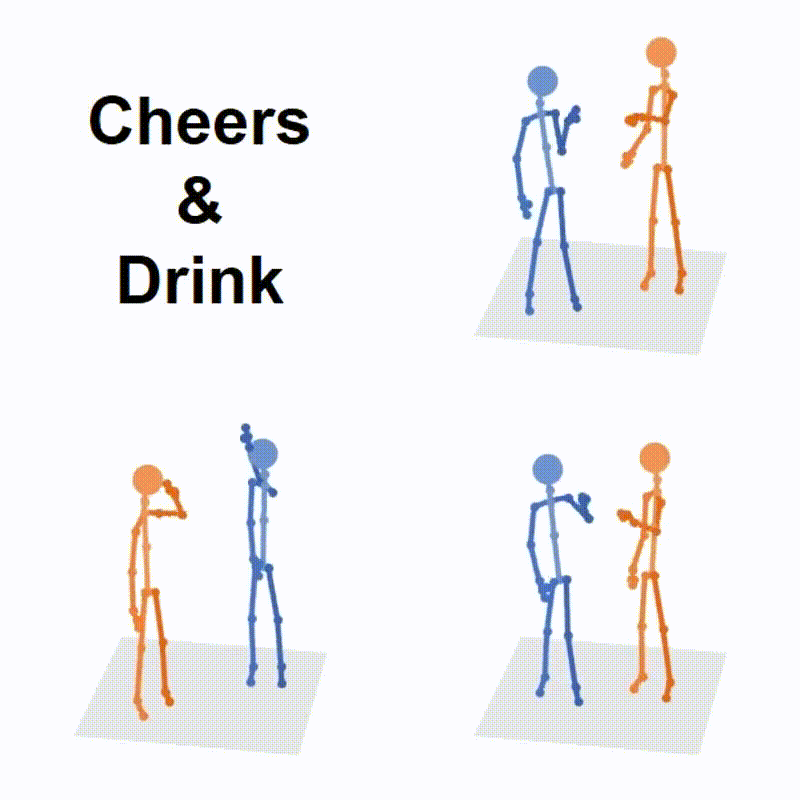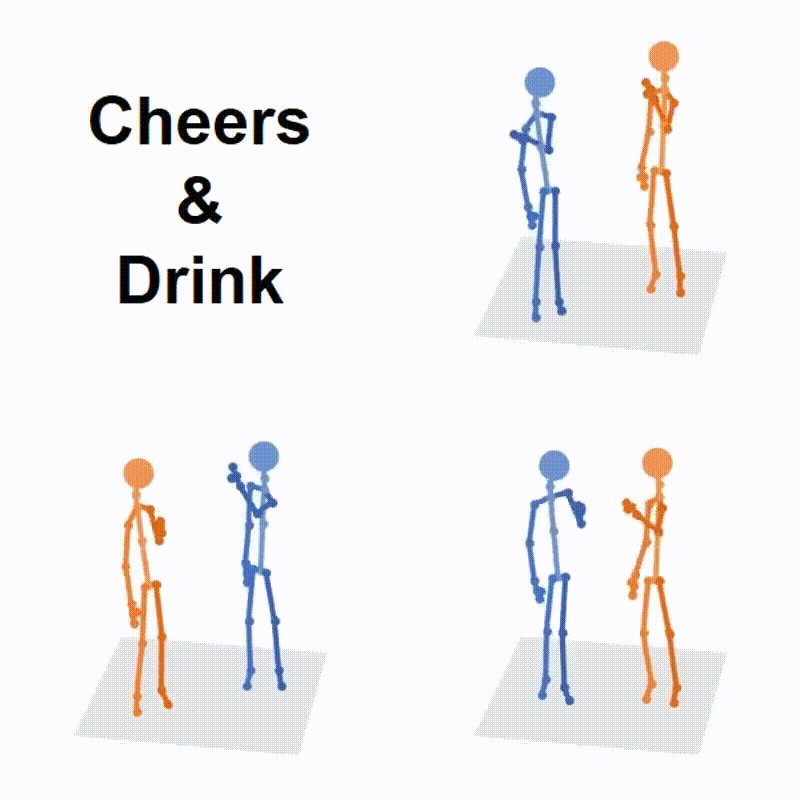
|
Liang Xu*, Ziyang Song*, Dongliang Wang, Jing Su, Zhicheng Fang, Chenjing Ding, Weihao Gan, Yichao Yan, Xin Jin, Xiaokang Yang, Wenjun Zeng, Wei Wu International Conference on Computer Vision (ICCV), 2023 arXiv Project Page Code (* denotes equal contribution) |
|
Ziyang Song, Bo Yang Advances in Neural Information Processing Systems (NeurIPS), 2022 arXiv Video Code |